World Models

World Models
Extremely smart as LLMs may seem, anyone who has worked with them in industry is well aware of their weak points. LLMs are still next-token predictors, sophisticated 'autocomplete' tools that usually produce perfectly written, seemingly reasonable and convincing replies, that turn out to be hallucinations, factually incorrect or even simply inaccurate due to the eagerness of the LLM to tell you what you want to hear.
We can keep training larger models on larger datasets; but as long as there is no paradigm shift, these models may never be able to really reason as a human does. A crucial piece seems to be missing in order to jump to the next level of AI reasoning. Here is where world models come in.
There seems to be a lot of hype recently about them recently, often being purported as "the next big step in AI" or "the future of research on AI", and strongly backed by authorities in ML like LeCun.

I decided to do some research over the weekend and put together a little summary about the basics of world.
Intuitions
Perhaps we can clearly highlight the limitations of LLMs first:
- LLMs operate in the discrete realm of language, not in the much more complex real world.
- LLMs don't have long-term memory or interactions. There is no mechanism for learning incrementally, or recalling facts beyond what's encoded in the static training weights.
- Reasoning and planning are weak, and not built in the architecture. We can try to guide it with prompts to perform chain-of-thought, but the models lack a fundamental mechanism to plan multi-step actions towards a goal.
In contrast, world models have a broader scope:
- World models have a physical component, they are meant to exist in the real world, to operate in environments governed by physical constraints. They are usually envisioned in the context of multi-modal sensory data as inputs (could be images, sensors, etc; not limited to text) ; and they are expected to navigate or act in the real world.
- World models learn to emulate causality and the laws of physics. They are thus able to carry out internal "simulation" and have planning abilities based on an agent forecasting outcomes and selecting optimal actions without direct environmental interaction.
- World models have the ability to learn over time.
Having said that, I feel that it's unfair and sensationalist and to directly compare LLMs to World Models. They tackle fundamentally different machine learning tasks: LLMs are supervised learning methods, (predict the next token); whereas World Models are tailored to planning / reinforcement learning tasks.
I remember at university, in the most elemental machine learning introductory course, being shown a chart like this in the first class:
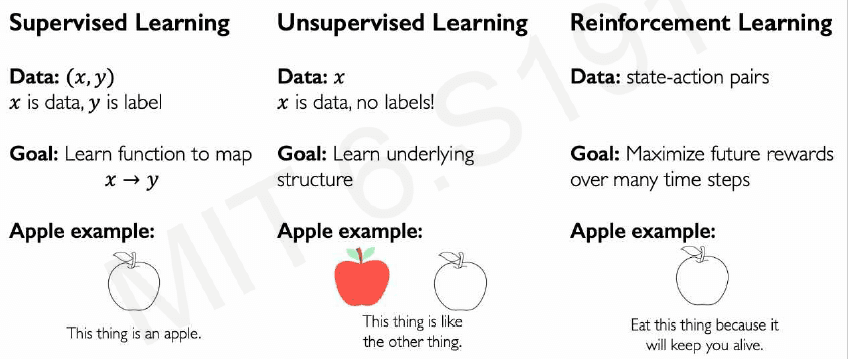
These are three different tasks and scenarios where ML is applied. Reinforcement Learning deals with dynamic agents that take actions in real or simulated worlds, and it is not intrinsically "better" or "superior" than supervised learning.
So, why world models now?
As I understand it, what many popular researchers are proposing right now is a shift of emphasis from supervised learning tasks (predicting the next token), towards reinforcement learning and particularly world models (predicting the real world).
And I suspect that many of the problems that are now solved with next-token predictors may be just cast as problems that an RL agent and tackle.
Deep dive into world models
In order to better describe what world models are and look into some SotA models and applications.
If you need a full recap of RL basics, check out my post reinforcement-learning-basics.
World Models: Preliminary definitions
The term “world model” remains somewhat loosely defined, and I would stick to the definitions presented in the paper Critiques of World Models, a 2025 survey of the field.
As with classical reinforcement learning algorithms, world models arise in the context of agent decision-making, and many see them as another strategy within the RL umbrella.
An agent is an autonomous system that acts in the environment (universe) and tries to achieve a goal.
We consider an environment with discrete timesteps indexed by t (continuous timesteps can be approximated by small discrete steps).
The agent takes the current world state and outputs the next action based on a distribution known as the policy.
The optimal agent is the one that best achieves its goals across all environments.
 At step the agent outputs action and the universe takes the current state and acction and outputs the next state based on a distribution
At step the agent outputs action and the universe takes the current state and acction and outputs the next state based on a distribution
The distribution of the interaction of trajectory until step given the current state is:
In each state the agent also receives a reward based on its goal . We evaluate the agent by its discounted cumulative reward:
Where is the discounted parameter that decays to zero with time, to penalize rewards too distant in the future.
The agent's long-term success can be measured by the expected value of the discounted cumulative reward, known as the value function
And the optimal agent in universe is the one that maximizes the cumulative reward (notice how we consider all possible policies):
An optimal agent, of course, may just not possible aside from simple scenarios like Go or Chess games, because it requires the agent to have access to the ground-truth world state from the universe to optimize. Imagine an agent to land on Mars, which has to rely on noisy sensors, for instance.
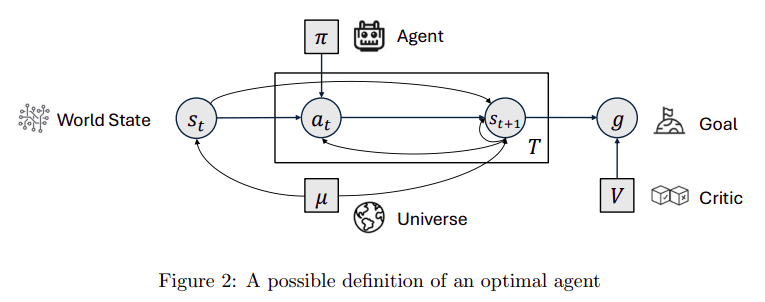
World Model Definition
A World Model (WM) is a function that takes previous world state and action and predicts or simulates the next world state , through a transformation function such as a conditional probability distribution :
A WM operates on an internal representation of the world state, denoted as the belief state , which is derived from sensory inputs via an Encoder . Note that there is no direct access to the true world state .
Given a proposed action , the WM predicts the next belief state according to the distribution - This predicted belief state then allows the agent to propose the next action, continuing the cycle of prediction and action up to a desired time horizon .
The agent can simulate multiple such sequences of proposed actions and belief states and select the actual action (upon observing ) based on some external function such as a Critic that evaluates the outcome against a given Goal.

Thus, a WM enables simulative reasoning or though experiments (informally dreaming). A general purpose WM enables simulation of diverse possibilities across a wide range of domains, enabling agents to reason about outcomes without direct interaction with the environment.
The WM should therefore learn to understand and predict concepts like:
- Physical dynamics: Mechanics of the real world, such as how water pours, how an object moves when thrown
- Emotional sates: Responses such as happiness, sadness, fear.
- Social situations
- Abstract thought processes such as logistics, tactics, strategies.
- Counterfactual world: "what if" scenarios
- etc etc etc
💡 *Combined with an encoder that estimates beliefs of the world states from arbitrary sensor observations, WM support machines to perform thought experiments computationally with controlled depth (number of steps) and width (number of trajectories) Once you have this, you can plan, predict, imagine, dream inside the model without touching the real environment every time. The model can, for instance, hypothesize about certain chains of actions. *
World Model Landscape
Let's explore the diverse areas where world models have been applied so far. A common denominator is that these systems focus on video/image generation in high quality.
| Area | Description | Example Models | Key Limitations |
|---|---|---|---|
| Gaming World Models | Simulate video-game environments using generative models capable of producing visual rollouts conditioned on actions. | Genie 2 (Google DeepMind), Muse (Microsoft), Oasis (Decart & Etched) | Domain-specific; limited to console-style or Minecraft-like inputs; shallow temporal coherence; short generation horizon (1–2 min) compared to multi-hour gameplay; not suitable for open-ended agent reasoning. |
| 3D Scene World Models | Stylized 3D scene generation and egocentric navigation; visually rich static scenes. | World Labs | Limited technical details; simulate mostly static scenes; lack dynamic agents, physics, or interactivity; unsuitable for tasks requiring physical causality or planning. |
| Physical World Models | Generative world models for robotics, driving, and embodied control with realistic low-level physics. | Wayve GAIA-2, NVIDIA Cosmos | Domain-specific; depend on task-specific sensors and architectures; do not scale to complex multi-agent or socially grounded environments. |
| Video Generation Models | General-purpose video synthesis from text or prior frames; generate fixed, non-interactive video trajectories. | OpenAI Sora, Google DeepMind Veo | No state/action representation; cannot branch on alternative actions; no counterfactual reasoning; not true world models (only video generators). |
| Joint Embedding Predictive Models (JEPAs) | Predict future latent embeddings rather than pixels; encoder-encoder architectures with energy-based losses. | V-JEPA, V-JEPA 2, DINO-WM, PLDM (Meta FAIR) | Mostly shown in toy tasks; unclear generalization ability; limited action complexity; early progress in robotics, but not yet scalable to high-complexity, long-horizon environments. |
Most fall short of enabling purposeful reasoning and planning in real world applications due to limitations in scope, abstraction, controllability, interactability, and generalizability. This may be why top scientists like LeCun are seeing to much unexploited potential in WMs.
💡 practical progress in WMs has been focused on generating videos
Industrial applications are few and very specific:
| Industry | World Model Usage | Examples | Maturity |
|---|---|---|---|
| Autonomous Driving | Predictive simulation for planning/action evaluation | Wayve GAIA-2, Tesla, NVIDIA Drive | High |
| Robotics | Manipulation forecasting, simulation-to-real | Covariant, Google DeepMind Robotics | Medium–High |
| Mobile/Consumer | Short-horizon prediction for AR/video | Apple Vision Pro, Google Pixel | Medium |
| Warehousing/Logistics | Robot coordination and fulfillment simulation | Amazon, Ocado | High |
| Industrial Digital Twins | Physical process forecasting | Siemens, Shell, BP, Rio Tinto | High |
Assorted thoughts about WMs and LLMs
- Autoregressive, generative models (e.g. LLMs) are doomed as they are guaranteed to make mistakes eventually, and can't model outcome uncertainties.
- Is really the text domain that limited? WM needs to be trained from sensory inputs (e.g. video). Much of that sensory data is low in semantic content and highly redundant, in contrast natural language is an evolved compression of human experiences, optimized over generations of abstract communication and conceptual reasoning. Text captures nor only physical realities but also mental, social, counterfactual phenomena that may be impossible to observe directly. Thus, the path towards general-purpose world modelling must leverage all modalities of experience, whether it'd be text, images, videos, touch, audio, or more. Overemphasizing video over text reflects a limitation or bias.
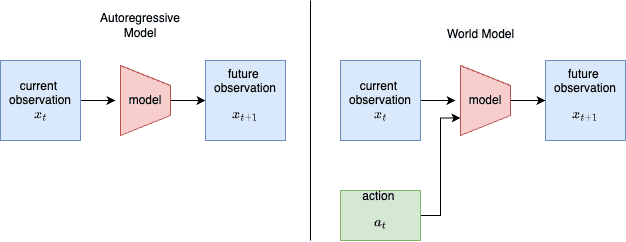
I liked this very simple diagram that shows how world models differ from e.g. LLMs, by extending the concept by incorporating actions into the equation.
Conclusion
Unlike large language models that conquered text, world models aim to give AI spatial intelligence - the ability to comprehend physics, predict future states, and create interactive 3D environments. This is in incredibly ambitious approach that is, at least from a theoretical perspective, extremely powerful.
The field seems to be very early and immature yet, with very limited practical applications and a strong focus on video generation. I am eager to see what is the future of WMs and whether they can actually debunk autoregressive foundation models as the smartest general-use AI technology out there.
Sources
https://worldmodels.github.io/ https://rohitbandaru.github.io/blog/World-Models/ https://arxiv.org/pdf/2507.05169